



Stay Updated with Everything about MDS
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.

Chilat Doina
June 29, 2026
Revenue is up. Your calendar is wrecked.
Customer support is asking ops where an order is. Ops is asking the warehouse why inventory is wrong. The warehouse lead is texting your ecommerce manager because only one person knows how to fix the bundle mapping. Your best employee can “just handle it,” which sounds efficient until that person takes a day off.
That's the point where a lot of 7-figure brands misread the problem. They think they need more people, more meetings, and more hustle. What they need is a different operating model. If you're serious about learning how to scale operations, stop asking how to push harder and start asking what breaks when volume rises.
The painful part of growth is that success creates the conditions for operational failure. The same scrappy habits that got you to 7 figures start punishing you on the way to 8. You can still get orders out. You can still patch the spreadsheet. You can still Slack the person who knows the workaround. But every one of those fixes increases fragility.
A typical pattern looks like this. Sales climb, then exception volume climbs faster. More split shipments. More stock discrepancies. More “one-off” customer issues. More manual refunds. More carrier escalations. You feel busier, but the business isn't becoming more scalable. It's becoming more dependent on heroics.
That's dangerous in a market where online demand keeps expanding. Global e-commerce sales are projected to reach $6.8 trillion by 2026 and account for 24% of all global retail, according to Stackscale's e-commerce growth analysis. The opportunity is massive. The penalty for weak operations is massive too.
Founders usually assume complexity is temporary. It isn't. Complexity compounds unless you deliberately design it out.
Three things are usually happening at once:
Practical rule: If your team needs more meetings to keep orders moving, your process is already under-designed.
The founders who break through this stage don't “get organized.” They rebuild the machine so daily execution doesn't depend on memory, proximity, or founder intervention. That's the shift from a big business to a durable one.
Most founders audit what's documented. That's the wrong target.
You need to audit what your team does when a product arrives late, inventory is off, an order gets stuck, or a customer asks for an exception. That's where scale breaks. The wiki might say one thing. Workflow often lives in Slack threads, side conversations, and the memory of whoever's been around longest.
A critical step is auditing the gap between process documentation and actual execution. Forrester research, cited in Tallyfy's process scaling guide, notes that AI and automation amplify whatever process they touch, good or bad. If the actual workflow is broken, automation scales the breakage.
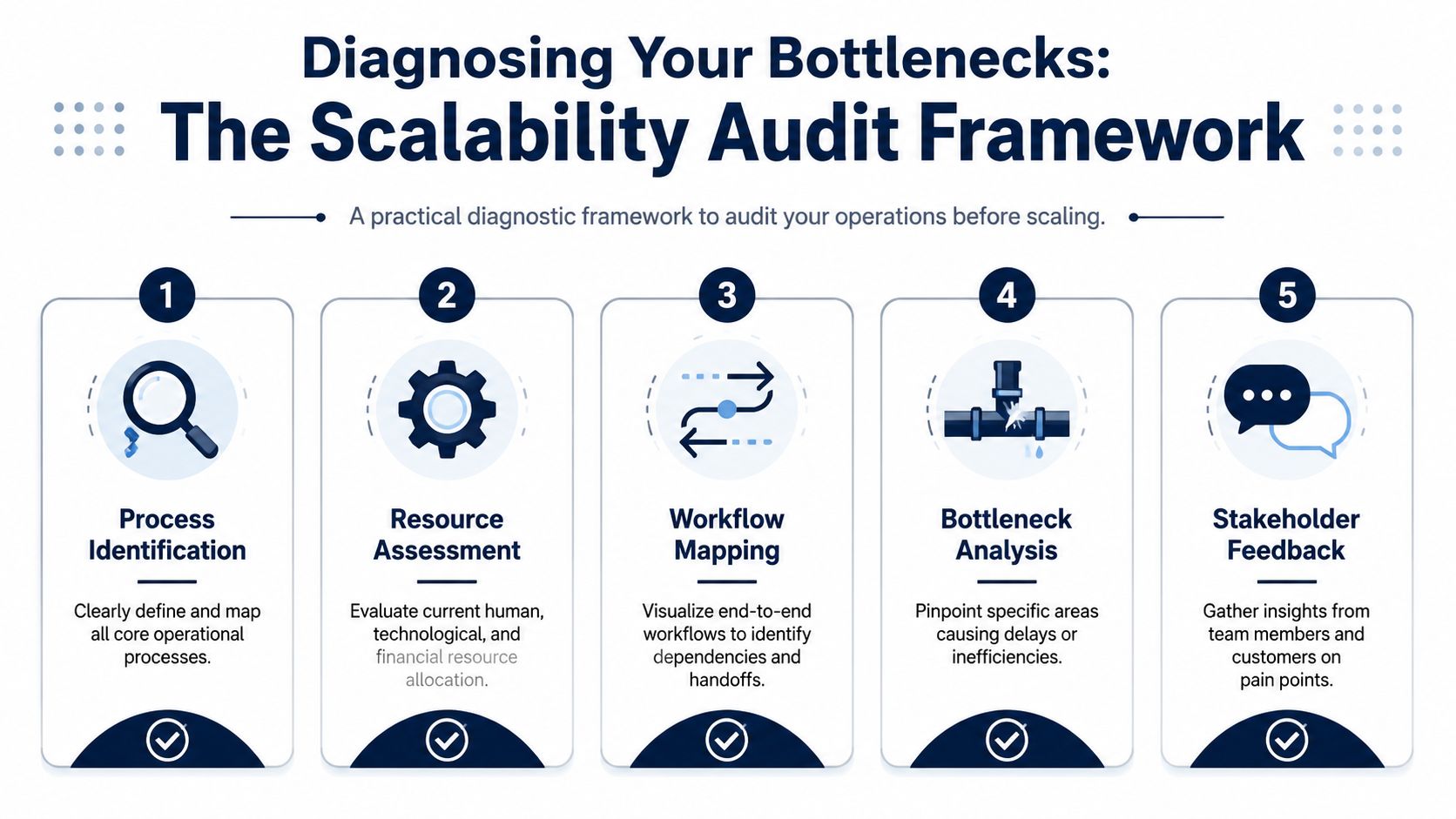
Don't begin with every process in the company. Start with the flows that create the most operational drag:
For each one, map the actual path. Not the clean version. The ugly version.
Ask your team to show you screens, messages, spreadsheets, and handoffs in sequence. If someone says, “Usually we just fix that manually,” stop there. That sentence is an audit finding.
The best audit questions are forensic, not theoretical.
Use prompts like these:
A good companion resource for this stage is MDS's internal perspective on how to improve operational efficiency, especially if you need a cleaner lens on handoff waste and repetitive manual work.
The process you should automate first is usually the one your team apologizes for most often.
Most operational audits fail because they turn into a documentation exercise. You don't need prettier SOPs yet. You need proof.
Track findings in a simple format:
| Workflow | Real-world workaround | Owner dependency | Business risk |
|---|---|---|---|
| Order routing | Team manually reroutes edge cases | Ops lead | Late shipments |
| Inventory updates | Spreadsheet used to correct mismatches | Inventory manager | Overselling |
| Returns handling | Support asks warehouse in chat | CX lead | Slow refunds |
Then rank each issue using three filters:
That's how you diagnose bottlenecks that matter. Not by asking what's documented. By identifying what your team does when documentation stops being useful.
Once you know where reality diverges from documentation, the work gets cleaner. Fixing scale is rarely about one tool or one hire. It's about tightening three things at the same time: people, process, and systems.
If one of those lags, the other two carry too much weight. That's when a warehouse management platform gets ignored, a new hire creates more confusion, or a beautifully documented workflow dies in practice because nobody owns it.
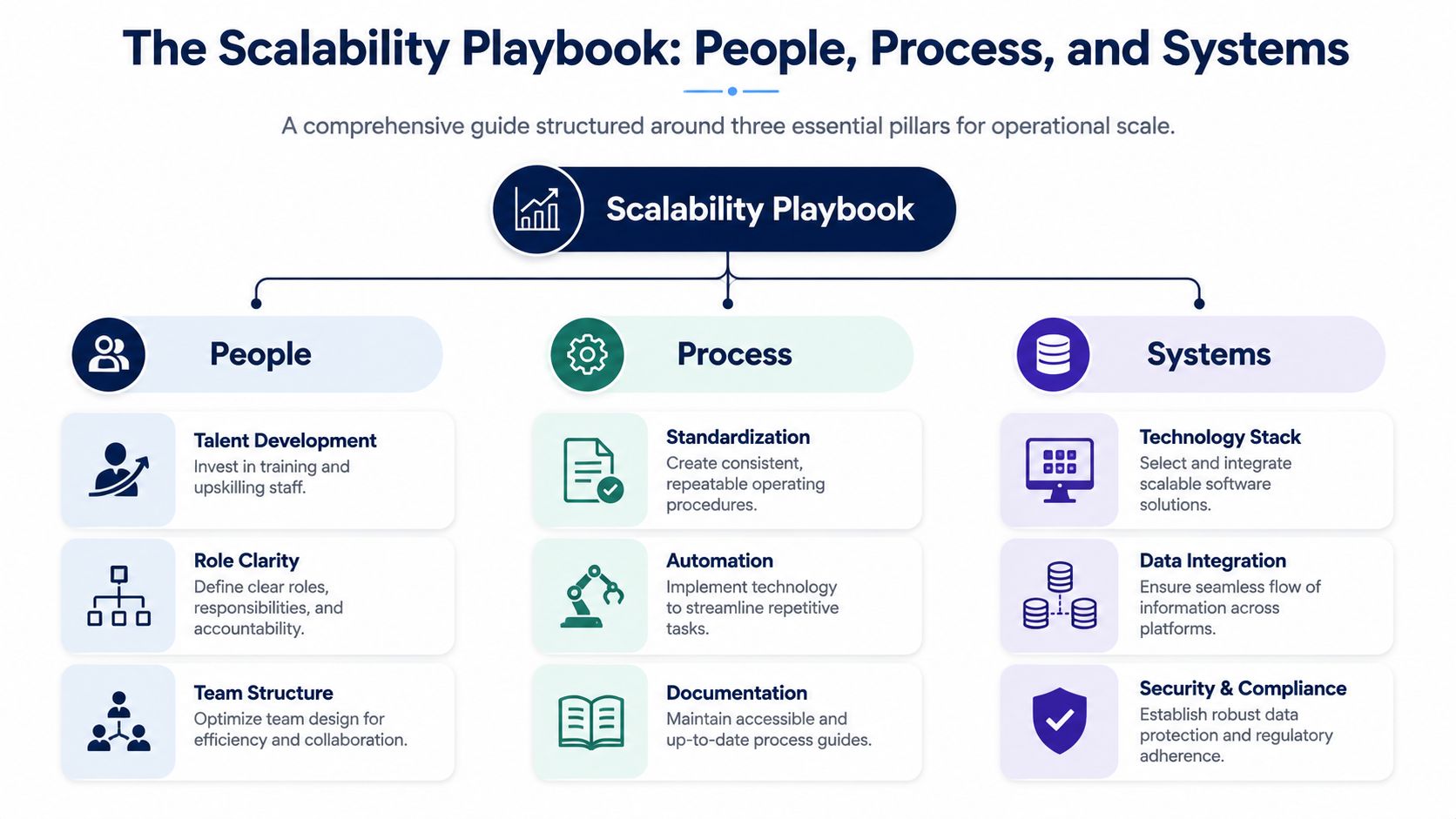
A lot of founders hire into chaos and call it delegation. That doesn't work. New people don't reduce complexity when ownership is fuzzy. They absorb it.
At the 7-figure stage, generalists are useful. Past that point, role boundaries start mattering more than sheer effort. You need clear accountability for inventory integrity, fulfillment exceptions, CX escalations, marketplace operations, and demand planning. Not because specialization is appealing in concept, but because scale punishes ambiguity.
The handoff matters as much as the role itself. If support can issue a replacement without creating an inventory adjustment, or if ops can move stock without finance understanding the downstream reconciliation impact, you haven't designed a team. You've created local optimizations.
Good process isn't the most detailed version. It's the version your team can execute under pressure.
That means standardizing the moments where mistakes cascade:
This is also where useful outside perspective helps. Some of the best service businesses scale by tightening repeatable delivery and ownership before they chase volume. The same principle shows up in these Silver Spoon Agency insights. Different model, same truth. Scale fails when execution depends on interpretation.
A short operational reset can help:
If two competent employees handle the same issue differently, you don't have a people problem. You have a process design problem.
Here's a practical test. Give the same exception scenario to two team members on different shifts. If the outcomes differ, your process is still tribal.
The systems conversation gets easier with a concrete example. This video is worth watching if you're thinking about operational structure from a founder's seat.
The primary advantage lies here.
The strongest brands don't scale by hiring proportionally with revenue. They scale by building data-driven operational structures early and centralizing inventory, orders, and delivery status into a single source of truth so manual coordination drops as complexity rises, as explained in Ecommerce Germany's guide to scaling e-commerce operations.
That principle changes how you evaluate software. Don't ask whether a tool has features. Ask whether it reduces cross-functional guessing.
Your core stack should answer, in near real time:
If your team has to compare Shopify, Amazon, your 3PL portal, a help desk, and a spreadsheet just to understand one delayed order, you don't have a system. You have a scavenger hunt.
The right architecture also needs fallback logic. Backup fulfillment locations, flexible carrier routing, and predefined exception rules matter more than another dashboard. Real scale comes from reducing the number of situations that require human coordination.
Founders love revenue dashboards because they're easy to read and emotionally satisfying. Operations doesn't break on revenue first. It breaks on hidden timing, accuracy, and exception signals that show up earlier.
That's why most “data-driven” businesses still manage by gut feel. They have numbers, but not operational visibility. A major pitfall in scaling is “no clear data, no smart decisions.” Successful scaling depends on data governance, real-time analytics, and automation tied to those insights, as described in Codup's breakdown of scaling challenges in ecommerce.
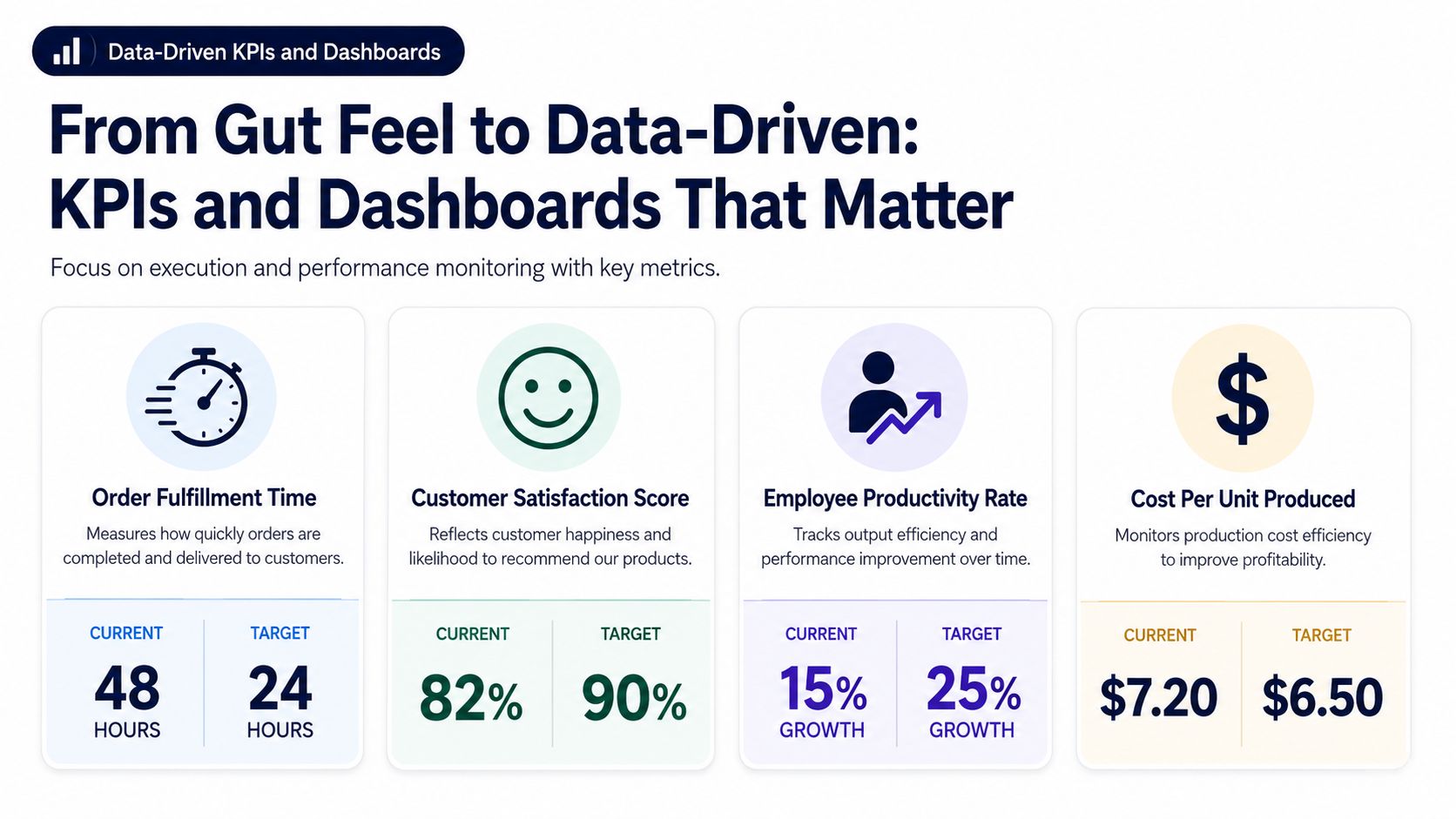
Lagging metrics tell you what already hurt you. Leading metrics tell you what's about to.
A useful operating dashboard usually includes:
Then keep a second layer of lagging outcomes:
The dashboard should tell a story. If release speed slows, support contacts often rise later. If inventory adjustments spike, oversells and split shipments usually follow. If escalations rise, your frontline team is either undertrained or constrained by policy.
A dashboard is only useful if everyone defines the metric the same way.
Data governance is paramount. “Shipped” can mean label created, handed to carrier, scanned by carrier, or delivered to customer. “Resolved” can mean ticket closed, issue fixed, or refund issued. If each team uses its own definition, leadership reviews become theater.
One practical move is to create a metric registry. Keep it simple. Metric name, owner, system of record, exact definition, and action threshold. That step alone eliminates a lot of fake alignment.
For a more grounded view of support-related waste, software access bloat, and where unused tooling hides inside service operations, this piece on how to find idle Zendesk licenses is a useful reminder that dashboards should expose inefficiency, not just performance.
A more ecommerce-specific KPI reference is this MDS guide to key performance indicators for ecommerce, especially if your current reporting still leans too heavily on top-line sales.
The best operations dashboard doesn't impress investors. It gives a team lead enough signal to fix tomorrow before customers feel it.
Don't review dashboards like a board deck. Review them like an operating room.
That means asking:
If your review cadence produces interesting discussion but no operational decisions, you're measuring for comfort. Not for scale.
A scalable operation runs on execution standards that people use. Not a dusty SOP folder. Not a founder's memory. Not “ask Sarah.”
The simplest way to think about execution is this. Every recurring task belongs in one of three buckets: automate it, keep it in-house, or outsource it. The mistake is treating those as cost decisions only. They're control decisions.
Most SOPs fail because they're written like compliance documents instead of working tools.
A good SOP is short, visual, and tied to the specific trigger that starts the task. It should tell the operator what to do, what to check, what to do if something is wrong, and when to escalate. If the task changes weekly, the SOP should be easy to update weekly.
Use a practical structure:
If you need a framework for building documentation your team will reference, this guide on how to create standard operating procedures is a strong starting point.
Not every task should stay internal. Not every repetitive task should be automated either.
Use this decision matrix:
| Function | Keep In-House When... | Outsource When... | Example Partner |
|---|---|---|---|
| Customer support escalations | The issue affects brand voice, retention, or policy judgment | The workflow is repetitive and requires extended coverage | Specialized CX agency |
| Warehousing and fulfillment | You need tight control over kitting, product handling, or custom packaging | You need broader geographic coverage, overflow capacity, or operational flexibility | 3PL |
| Creative production ops | Creative is core to acquisition and requires fast founder feedback | Volume-based production is delaying strategic work | Creative operations partner |
| Inventory planning support | Product mix and channel strategy are tightly linked | Reporting and replenishment admin are consuming senior bandwidth | Planning consultant or analyst partner |
| Returns processing | Product inspection affects resale, warranty, or compliance decisions | Physical processing is slowing internal teams | Reverse logistics provider |
Automation works when the task is stable, high-frequency, and rule-based. It fails when the workflow still depends on judgment, undocumented exceptions, or bad data.
Before automating, ask:
Here's the rule most founders learn late. If a task changes every month, document it first. If it repeats cleanly, automate it. If it's necessary but non-core, outsource it.
Outsourcing goes wrong when founders use it to avoid making decisions. A partner can execute the work, but they can't supply missing standards.
If you move fulfillment to a 3PL without clear receiving rules, exception handling, and service levels, the chaos just changes address. If you outsource support without policy trees, your ticket volume might look cleaner while refund leakage climbs unnoticed.
The right partner setup includes:
Outsourcing should reduce founder involvement in repetitive execution. It should not reduce your visibility into business-critical signals.
The expensive mistakes aren't dramatic when they start. They usually look rational. A new hire. A system migration. A warehouse move. More ad spend. A product expansion. Each one seems manageable on its own. Together, they expose every weak assumption in the business.
The most common bad assumption is that growth will solve underlying weakness. It won't. A critical pitfall is scaling before the business is consistently profitable. Expanding a lucky bucket without fixing micro-level issues leads to failure, and brands need stable recurring revenue, healthy margins, and customer lifetime value that clearly outweighs acquisition costs before they push harder, as explained in Ayokay's view on knowing when to scale.

One seller cleaned up top-line revenue by pushing a winning SKU harder across more channels. The problem wasn't demand. The problem was fulfillment complexity and thin contribution margin. More sales created more operational strain and less financial room to absorb it.
Another brand implemented automation on top of unstable workflows. The software wasn't the issue. The team had never resolved who owned exceptions, so the system routed bad inputs faster and at greater scale.
A third business hired managers before clarifying decisions. Suddenly every issue had more visibility and less accountability. Meetings multiplied. Resolution speed didn't.
A fourth outsourced a key function to gain bandwidth, but didn't define service levels, escalation paths, or reporting. The founder delegated activity, not control. They got distance from the work, not clarity.
The brands that scale well tend to be boring in the right places.
They challenge growth moves with questions like:
Broken economics don't become healthy at larger scale. They become harder to unwind.
They also resist one of the most common founder instincts. They don't keep adding people to absorb ambiguity. They force clarity first. Ownership first. Definitions first. Then they hire or automate against a stable operating model.
If your business gets bigger but requires more founder intervention, you haven't scaled operations. You've enlarged the blast radius.
The ultimate goal is a company that handles more orders, more channels, more geographies, and more complexity with better visibility and fewer emergency decisions. That only happens when process reflects reality, systems reflect process, and leadership stops confusing motion with capacity.
Learn how to scale operations by treating tribal knowledge as a liability, not an asset. Audit what really happens. Standardize what must be repeatable. Centralize the data that drives decisions. Then choose carefully what to automate, what to own, and what to delegate.
If you're already past the beginner advice stage and want sharper operator-level perspective, Million Dollar Sellers is where serious ecommerce founders compare notes on what proves effective at scale. It's an invite-only community built for sellers who want better decisions, tighter execution, and access to peers who've already made the expensive mistakes.
Join the Ecom Entrepreneur Community for Vetted 7-9 Figure Ecommerce Founders
Learn MoreYou may also like:
Learn more about our special events!
Check Events.svg)
.svg)
.svg)

.svg)