
Chilat Doina
May 31, 2026
A/B testing is a randomized experiment that compares Version A against Version B to prove which page, ad, or email makes you more money. In practice, a result is often considered statistically significant when the p-value is below 0.05, meaning there's less than a 5% chance the observed difference is random.
If you're running a serious ecommerce brand, this isn't a nice-to-have. It's a capital allocation tool. Every time you change a product page, a cart flow, an email subject line, or an offer without testing, you're making a bet with real traffic and real revenue.
Most founders already know this in theory. The problem is execution. A team changes the hero image because a competitor did it. A designer pushes a new PDP layout because it "feels cleaner." An agency rewrites the headline and declares a win after a few good days. Revenue moves, or it doesn't, and nobody can say with confidence what caused it.
That's where A/B testing matters. Not because it's academic. Because once you're operating at 7, 8, or 9 figures, bad decisions get expensive fast. Traffic is valuable. Creative cycles are limited. Your team can waste months on testing theater that produces dashboards, meetings, and opinions, but no reliable answer.
The useful way to think about what is A/B testing is simple. It's the discipline of changing one meaningful variable, splitting traffic fairly, and letting customer behavior decide whether the change deserves a full rollout.
Founders guess more than they'd like to admit.
You swap a headline on your landing page. You move reviews higher on the product page. You change the add-to-cart button copy because someone on the team says it sounds stronger. Then you watch revenue for a few days and try to reverse-engineer meaning from noisy data.
That isn't optimization. That's expensive improvisation.
Gut instinct still has value. It helps you spot weak pages, stale messaging, and customer friction. But instinct should generate hypotheses, not final decisions.
A/B testing gives you the discipline to separate those two jobs. Your team can still say, "I think a tighter value proposition will increase product page conversions." The test is what tells you whether that belief holds up when real buyers see it.
For operators scaling paid traffic, that matters because every untested change can distort your read on the funnel. You might blame Meta, Amazon listing quality, or email fatigue when the issue is a checkout tweak that hurt conversion.
Practical rule: Use opinions to decide what to test. Use experiments to decide what to ship.
Teams that get this right build a culture around evidence, not hierarchy. If you want a broader framework for that operating style, this guide to data-driven decision-making is worth reviewing alongside your testing process.
A good test has an expected upside. A bad test just consumes traffic.
That distinction matters more as your brand grows. High-traffic pages, paid landing pages, product detail pages, and checkout steps deserve disciplined experimentation as their performance directly affects business outcomes. Tiny cosmetic changes on low-impact pages usually don't.
That also explains why newer workflows around AI-powered conversion optimization are getting attention. They can help teams generate stronger hypotheses and move faster, but they still don't replace the core discipline. If the setup is sloppy, faster testing only gets you wrong answers sooner.
The point isn't to test everything. It's to stop making important growth decisions on vibes alone.
At the core, A/B testing is simple. You keep your current version as control A, create a new version as variant B, split traffic between them, and measure which one performs better on a defined business outcome.
Imagine two sales associates in a physical store. One uses your current opening script. The other uses a revised one. If you want a real answer, you don't also change the store music, product placement, pricing, and staffing at the same time. You isolate the script.
Digital testing works the same way.
If you're testing a product page headline, keep the images, pricing, reviews, shipping promise, and layout the same. If you change three things at once and sales go up, you still don't know what caused the lift. That's why strong A/B tests focus on one primary variable.
This is the definition that matters in practice. A/B testing is a randomized experiment that compares two versions of a single variable, commonly called control A and treatment B, to determine which one performs better. Statistically, it's framed as a two-sample hypothesis test, where the result is judged against the null hypothesis that any observed difference is due to chance. A p-value below 0.05 is a common threshold for significance, meaning there's less than a 5% chance the result is random, as outlined in Wikipedia's explanation of A/B testing.
The random split is what makes the result useful.
If your VIP email segment gets one version and first-time visitors get another, you aren't running a clean test. You're comparing different audiences. The same goes for sending mobile users to one version and desktop users to another unless that's the exact thing you're trying to analyze.
A clean A/B test does three things well:
That applies whether you're testing a Shopify landing page, an Amazon image stack, or an email subject line. If you're selling on marketplaces, this practical guide on how to boost Amazon performance with A/B tests is a useful complement because it shows how the same logic applies in Amazon-specific workflows.
The best A/B tests aren't creative exercises. They're controlled business decisions.
Once you understand that, the question shifts from "what is A/B testing?" to "which decision is important enough to deserve proof?"
The brands that benefit most from testing aren't the ones obsessed with button colors. They're the ones using tests to de-risk decisions that affect acquisition, conversion, and retention.
An Amazon operator usually isn't testing for curiosity. They're trying to answer a blunt question: does this title, image sequence, or A+ module make the listing more productive?
A common pattern looks like this. The existing listing leans technical. It describes features well, but it doesn't do enough selling. The test version reframes the same product around the buyer's use case, tightens the main image support set, and clarifies the value proposition in A+ content. The goal isn't prettier content. The goal is higher conversion from the same demand.
That's why top sellers don't test random assets. They test the assets buyers use to make decisions.
On a DTC site, the biggest wins often come from message-market fit on high-intent pages.
A founder sends paid traffic to a landing page with a polished but vague headline. The page looks premium, but the promise is soft. A challenger version says exactly who the product is for, what pain it solves, and why it's different. Nothing else changes. Same product. Same traffic source. Same offer mechanics. The only difference is clarity.
When that kind of test wins, it usually teaches something larger than the headline itself. It tells you the market wants specificity. That insight can then shape ad creative, PDP copy, and email messaging.
If your team is working on those kinds of funnel decisions, this resource on how to improve ecommerce conversion rates pairs well with a testing roadmap because it helps prioritize the pages that matter most.
Email is one of the cleanest environments for A/B testing because the variable can be tightly controlled.
Subject line tests are the obvious example. One version leads with urgency. Another leads with curiosity. Same list quality, same send timing framework, same offer inside the email. If one version gets materially better engagement and downstream revenue, that's useful signal.
The same applies inside the email body. Founders often learn that the story they want to tell isn't the story the customer needs to hear first.
Here are the channels where strong sellers usually get the fastest lessons:
That last point matters more than many brands admit. When your offer depends on image-led clicks, thumbnail quality can change who even enters the funnel. Teams evaluating new visual directions often pull inspiration from resources on best thumbnail maker tools, not because thumbnails solve conversion alone, but because top-of-funnel presentation affects the quality of traffic reaching the test.
If a test changes how buyers understand the offer, it can change the whole funnel. That's where the real upside sits.
A poorly designed test is worse than no test. No test leaves you uncertain. A bad test gives you false confidence.

Most weak tests start with vague intent.
"Let's see if this page does better" isn't a hypothesis. A real hypothesis has cause, effect, and a reason. Example: if we move subscription savings higher on the page, more shoppers will choose the recurring purchase option because the value is clearer before they scroll.
That kind of framing forces better thinking. It also makes the result easier to interpret later.
According to GrowthBook's explanation of A/B testing, A/B testing is strongest when it's treated as a randomized controlled experiment. Each user should be assigned to only one variant, all non-tested elements should stay constant, and only one feature should change so you can attribute causality to that change. A predefined hypothesis and metric set should be established before launch to avoid misleading results.
Before anyone touches design or code, answer these questions:
What is the one thing we're trying to prove?
If the answer includes multiple ideas, narrow it.
What is the primary KPI?
Pick the metric that connects to the business decision. For a PDP test, that may be product conversion. For a cart test, it may be checkout completion. For an email test, it may be click behavior or downstream purchase.
What must stay unchanged?
Lock this down upfront so the team doesn't keep "improving" the page mid-test.
Who should be included?
New visitors, returning visitors, paid traffic only, mobile only. Define the audience intentionally.
What happens if the test wins?
If rollout would still be blocked by opinion or internal politics, don't run the test yet.
| Test Area | Primary KPI | Secondary KPI |
|---|---|---|
| Product detail page | Conversion rate | Add-to-cart rate |
| Cart page | Checkout completion | Average order value |
| Checkout flow | Purchase completion | Drop-off by step |
| Landing page | Conversion rate | Click-through rate |
| Email subject line | Open behavior | Click-through rate |
| Email body content | Click-through rate | Revenue per send |
Many brands slip at this point.
You can't route users unevenly, edit the page halfway through, and then trust the result. You also can't test a new bundle offer during a promo spike and expect the answer to generalize cleanly.
Use this operating checklist:
What works at scale is boring discipline. The test setup should feel almost rigid. That's a feature, not a bug.
A results dashboard can look decisive when it isn't.

You launch a test on Monday. By Wednesday, variant B is ahead. The temptation is obvious. Call the winner, push it live, and move on. That's how teams fool themselves.
The right way to read A/B results is not "which line is higher today?" It's "how confident am I that rolling this to everyone won't backfire?"
For simple tests, one useful rule of thumb comes from A Smart Bear's explanation of A/B testing statistics. To achieve 95% confidence, the observed difference has to be large enough that it's unlikely to be random chance. In simple terms, that often corresponds to a chi-squared value over 3.8. The same source notes that for 99% confidence, the value is about 6.6, which is why a rough threshold of 4 often appears in simplified rules. It also shows why small samples are dangerous. With fewer trials, the observed effect has to be much larger to clear the statistical hurdle.
That's the piece many operators miss. Small tests produce dramatic-looking winners all the time. Most of them disappear when more data arrives.
A temporary lead is not the same thing as evidence.
When you're looking at a test result, ask these questions in order:
This is why many experienced teams monitor tests inside a broader performance metrics dashboard, not in isolation. A page-level win that hurts downstream revenue isn't a win.
The practical business analogy is simple. One strong Saturday doesn't prove you've fixed retail. One strong week in a split test doesn't prove you've found a scalable winner either.
A founder who understands this reads significance as protection against false certainty. You're not asking whether the test result feels promising. You're asking whether the evidence is strong enough to justify a rollout decision.
For a visual walkthrough of how marketers think about this process, this explainer is useful:
The most expensive mistake isn't losing a test. It's rolling out a fake winner across your whole funnel.
A lot of ecommerce brands are lying to themselves with data.
Not intentionally. But the outcome is the same. They run flawed tests, read noise as truth, and then ship decisions that hurt revenue while feeling smart because a dashboard exists.

The first failure mode is ending the test the moment one version looks ahead. Teams do this constantly. They peek, get excited, and stop early. That turns normal variance into fake certainty.
The second is testing too many changes at once. New headline, new imagery, new layout, new offer stack. If it wins, nobody knows why. If it loses, nobody knows what to fix.
The third is ignoring the context around the test. Promotion periods, inventory issues, seasonality, and channel mix shifts can all muddy the read.
This is the part most beginner content skips. Sometimes A/B testing is the wrong tool.
A valid test needs enough traffic and a large enough effect to be detectable. For low-traffic sites or products, running tests can be a waste of time because they may never reach statistical significance. Nielsen Norman Group notes that test duration depends on sample size, baseline rate, minimum detectable effect, and significance, which makes many tests impractical for smaller sellers or low-volume pages, as explained in their article on A/B testing.
If you have a low-traffic PDP for a niche SKU, don't force a formal split test just to say you're "data-driven." You're often better off using qualitative feedback, session reviews, support tickets, merchandising logic, or applying learnings from higher-traffic sibling pages.
Operator's rule: Don't test pages that can't produce decision-quality evidence in a reasonable time.
Use these rules to stay honest:
Strong operators don't just ask, "Can we run a test?" They ask, "Will this test produce an answer good enough to change a decision?"
That's the difference between experimentation and theater.
Once the basics are handled, higher-volume brands can move beyond the standard fixed split.
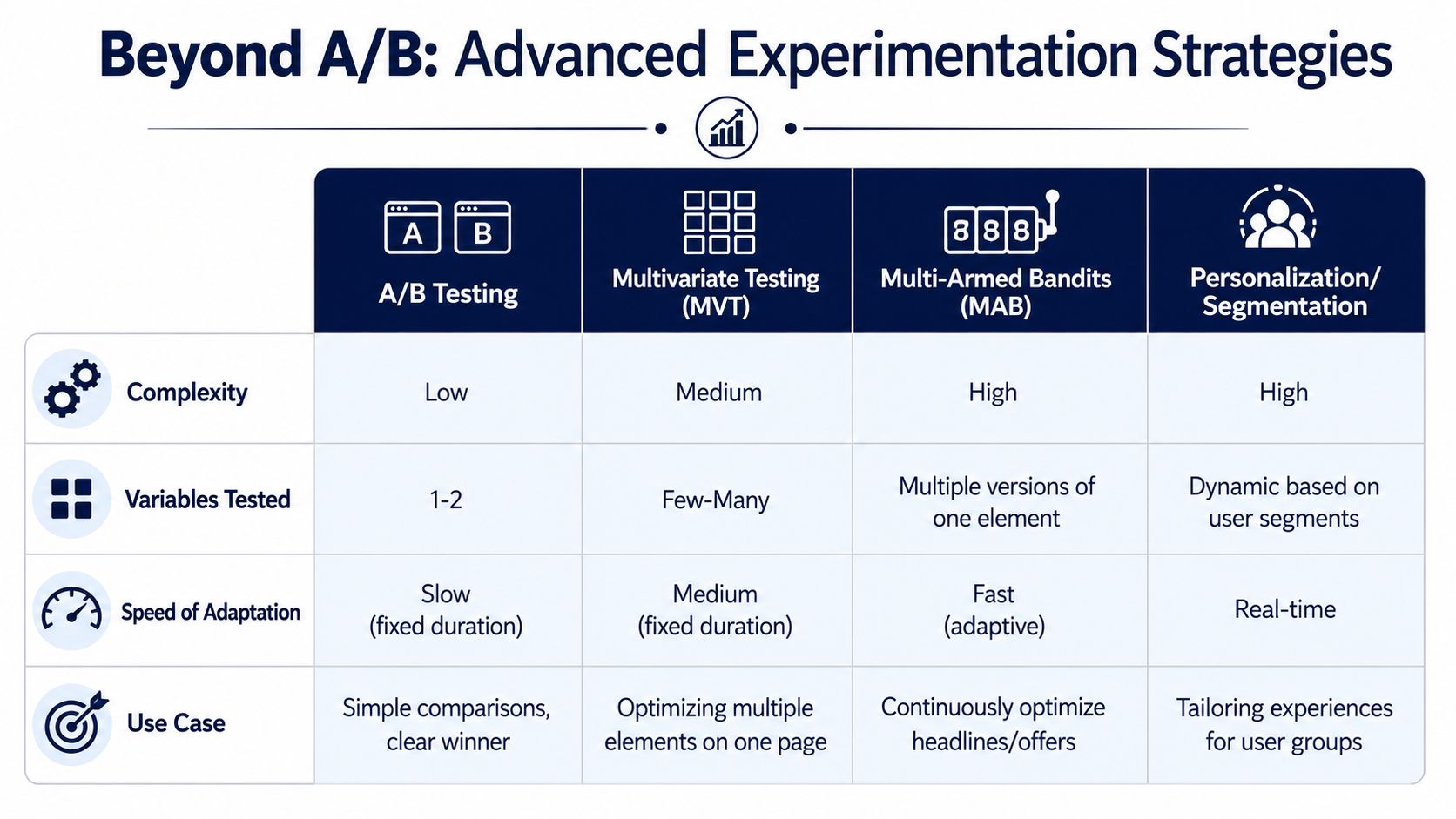
A/B testing is still the best tool when you need a clean answer to a focused question.
Multivariate testing becomes more useful when a page has several interacting elements and you want to understand combinations, not just one isolated change. It's more demanding operationally, so it makes more sense when traffic is strong and your team already runs disciplined experiments.
Multi-armed bandits are different. Instead of keeping a rigid split throughout the test, they can shift more traffic toward stronger-performing variants as evidence builds. That makes them attractive when speed matters and you don't want to keep donating equal traffic to weaker versions.
Personalization and segmentation take it one step further. Instead of finding one universal winner, you try to match different experiences to different customer groups.
Modern experimentation is also changing because platforms are using machine learning to automate parts of the process. Salesforce describes advanced A/B testing as moving beyond static 50/50 splits toward adaptive experimentation where machine learning can dynamically allocate traffic and automate parts of execution, as described in Salesforce's overview of A/B testing.
That matters in ecommerce because conditions change fast. Offers rotate. traffic sources shift. Creative fatigue sets in. By the time a slow static test finishes, the market context may already be different.
The mature view is this: basic A/B tests help you prove isolated decisions. Advanced experimentation helps you operate faster when your brand has enough volume to support it.
If you're building at the level where experimentation affects real revenue, Million Dollar Sellers is where serious ecommerce founders compare what's working across Amazon, DTC, and omnichannel. It's an invite-only room built for operators who want better decisions, faster execution, and fewer expensive mistakes.
Join the Ecom Entrepreneur Community for Vetted 7-9 Figure Ecommerce Founders
Learn MoreYou may also like:
Learn more about our special events!
Check Events


