
Chilat Doina
May 2, 2026
You’re probably feeling it already. Revenue is up, order volume is less predictable, your catalog is wider, and the old operating model that got you here now leaks cash in places that don’t show up until month-end. Freight spend creeps higher, inventory lands in the wrong warehouse, your team starts expediting avoidable mistakes, and customer support absorbs the fallout.
At that stage, most brands attack the symptom they can see. They renegotiate rates, push a 3PL harder, or buy another app. That rarely fixes the underlying issue. Supply chain efficiency breaks when diagnostics, inventory policy, fulfillment design, and decision systems stop working as one operating system.
The brands that scale cleanly treat supply chain as infrastructure. They don’t ask only, “How do we lower shipping cost?” They ask, “How do we free cash, improve delivery promise accuracy, reduce fire drills, and create room for growth without adding fragility?” That’s the lens that matters when you’re building a serious e-commerce business and trying to figure out how to improve supply chain efficiency without creating a mess somewhere else.
A lot of founders still treat supply chain like back-office plumbing. Keep product moving, keep returns under control, and squeeze a few points out of freight if possible. That mindset caps growth because it misses what efficient operations deliver for a scaling brand.
An efficient supply chain improves margin, but it also improves speed of decision-making, cash deployment, and customer experience consistency. Those three things matter more at scale than most operators admit. If your replenishment cycle is sloppy, your best ad campaign can create stockouts. If your fulfillment network is wrong, growth in a new region destroys contribution margin. If your purchasing process is slow, your team buys reactively and pays for urgency.
The biggest shift is mental. Stop viewing operations as a cost center and start treating it as the machine that determines how much profitable growth your business can absorb. Brands with stronger operating discipline can launch more SKUs, enter more channels, and tolerate more volatility because the system underneath them doesn’t break every time demand changes.
That’s why supply chain work belongs in the same conversation as pricing, channel mix, and unit economics. If you’re not tying operations back to gross margin, working capital, and payback periods, you’re leaving strategy incomplete. This is the same reason founders who understand unit economics in e-commerce usually make better operations decisions. They know every delay and every bad inventory call eventually shows up in cash.
There’s also a facilities layer that many product businesses overlook once they expand into regional operations, showrooms, or hybrid fulfillment footprints. Teams managing multiple physical sites often need tighter maintenance and operating discipline to keep workflows stable. In that context, a resource like facility management in UAE is useful because operational efficiency doesn’t stop at inventory or transportation. It includes the reliability of the physical environments where stock, labor, and service intersect.
Efficient supply chains don’t just save money. They let a brand keep promises without overspending to recover from preventable mistakes.
Most brands diagnose supply chain problems by staring at freight invoices. That’s too late and too narrow. You need a health check that shows where time, cash, and reliability break down from purchase order to doorstep.
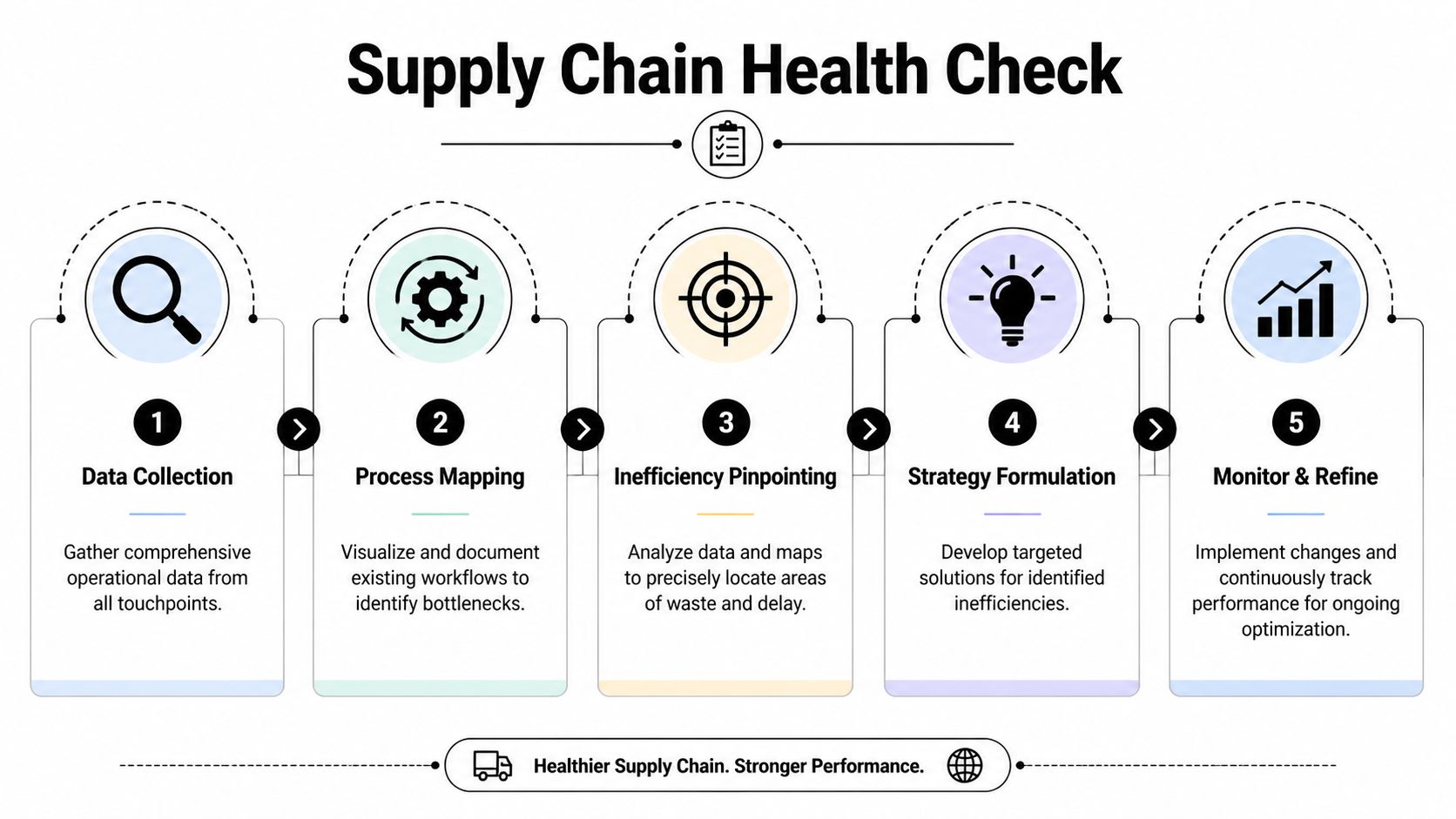
Vanity metrics hide bad systems. “Average shipping cost” tells you almost nothing if your team is constantly splitting shipments, rerouting inventory, or paying for late replenishment. The better approach is to use a short set of metrics that reveal structural issues.
I’d start with these:
If your team needs a practical way to centralize those metrics, build them into a single performance metrics dashboard for operational visibility. The point isn’t prettier reporting. The point is creating one operating view that finance, operations, and inventory planners can all use.
Once the KPI set is clean, map the process end to end. Most inefficiency lives in handoffs. Departments rarely see that because they’re looking at their own step, not the full path.
Use one real order and one real replenishment cycle as your base cases. Trace them through every touchpoint:
This exercise usually exposes one of three patterns.
| Failure pattern | What it looks like | What it usually means |
|---|---|---|
| Data lag | Teams make decisions from stale inventory or demand views | Systems aren’t synced or reporting is delayed |
| Policy conflict | Sales, finance, and ops optimize for different outcomes | Leadership hasn’t aligned on trade-offs |
| Manual patching | Staff rely on spreadsheets, Slack messages, and tribal knowledge | Process design is weak, not just labor capacity |
Don’t produce a hundred-slide deck. Produce a working document with four parts:
Practical rule: If a process only works because one experienced employee remembers the workaround, that process is broken.
A good diagnostic should feel slightly uncomfortable. It should show where your brand is paying a hidden tax for growth. Once you have that baseline, every operational improvement becomes measurable instead of anecdotal.
A $12 million brand can post record revenue and still run its supply chain like it is guessing. The pattern is familiar. Bestsellers go out of stock right after a campaign hits, slow movers pile up in the wrong node, and the finance team sees inventory rising faster than contribution margin.

At that stage, inventory is no longer an operations detail. It is a capital allocation decision that affects cash, service levels, and how much room you have to scale into the next demand spike without creating operational debt.
Basic min-max settings and spreadsheet reorder points hold up longer than they should. Then channel mix expands, promotions get more aggressive, lead times move around, and the model starts failing in expensive ways. Excess stock hides weak planning for one part of the catalog. Stockouts expose it in another.
The fix is to run inventory as part of a coordinated efficiency engine. Diagnostics identify where accuracy breaks. Fulfillment design determines where inventory should sit. AI-assisted planning improves how fast the team reacts when demand, supplier performance, or channel velocity changes. Treating those as separate projects is how brands stay stuck.
Historical sales matter, but historical averages are a blunt instrument. Better planning uses current channel velocity, promotion calendars, inbound delays, supplier constraints, and recent demand shifts by SKU group. The goal is not perfect prediction. It is faster correction.
McKinsey notes that AI-enabled supply chain management can improve forecasting and inventory decisions when companies feed models with broader operational signals instead of relying on static planning inputs. The practical takeaway is simple. Planning gets better when the model sees what your operators already know is changing. Read the analysis at McKinsey on AI in supply chain planning.
I have seen the biggest gains come from cadence and signal quality before software sophistication. If one planner is exporting Amazon, Shopify, ERP, and 3PL data every Monday, your process is already behind the business by the time the file is finished.
Uniform inventory rules create uneven results. A hero SKU with stable replenishment, a seasonal item with promotion spikes, and a long-tail product with low weekly turns should not share the same service target or reorder logic.
Use a simple operating structure that teams can maintain:
Documented inventory management best practices for scaling brands help here because they force consistency across reorder logic, receiving rules, ownership, and exception handling.
Purchase discipline matters too. Sloppy PO structure creates downstream errors in receiving, matching, and supplier follow-up. Teams cleaning up that process can use the Monopack ltd PO guide as a reference for tighter purchase order controls.
Static safety stock gives teams a false sense of control. It ignores what changed this week. Supplier lead times slip. A retail partner order lands early. Meta spend scales up faster than planned. A marketplace listing gets traction in one region and flatlines in another.
Dynamic buffers work better because they adjust to current conditions. Raise protection on SKUs with unstable supply. Lower it where lead times have normalized and sell-through is cooling. Keep monthly S&OP-style reviews for larger buy decisions, then run a weekly exception review for the SKUs that need intervention now.
AI proves its value here. It does not replace operators but instead identifies pattern shifts early enough to intervene before cash flow or service levels suffer. For 7 to 9 figure brands, that process typically involves exception-based planning, risk scoring for inbound supply, and suggested reorder modifications based on real-time demand patterns.
Inventory should justify the cash it consumes. If a unit does not protect revenue, margin, or strategic availability, it is probably sitting on the balance sheet for the wrong reason.
What works
What fails
The best inventory systems do two things at once. They free cash and raise service reliability. That is the point where inventory stops behaving like a liability and starts acting like an asset.
Q4 exposes weak network design fast. Orders spike on the coasts, your single warehouse sits in the wrong zone, parcel costs climb, and customer promise dates slip at the same time. A lot of operators blame the carrier or the 3PL first. In brands at scale, the bigger issue is often network architecture.

A single-node setup can work well into eight figures because it keeps receiving, storage, and inventory control simple. It also hides costs that get harder to absorb as order density spreads across regions and channels. You start paying more in zone charges, split shipments, transfer work, and service failures during peaks. One building also concentrates risk. If labor gets tight, throughput drops, or weather hits that region, the whole business feels it.
The right answer is not “add more warehouses” as a default. The right answer is to build a network that matches demand patterns, margin structure, supplier reliability, and your ability to orchestrate inventory across nodes.
The standard argument for one warehouse is inventory efficiency. In a narrow sense, that is true. One pool reduces duplication and can make replenishment easier to control.
For growth-stage e-commerce brands, that benefit has to be weighed against speed, parcel spend, and resilience. If 60 percent of your orders ship to regions far from your only node, centralization stops being efficient. It becomes a recurring tax on every order.
Pitney Bowes outlines the broader operating logic in its overview of ecommerce supply chain management. Multi-node networks are used to place inventory closer to demand, shorten delivery zones, and reduce dependence on one facility. If you want hard benchmark numbers, cite the source that owns them directly. FFOrder publishes its own ecosystem findings on multi-node fulfillment performance, and any claim on deadstock reduction or delivery acceleration should link to the original FFOrder dataset, not a secondary summary. The same rule applies to any specific shipping cost reduction figure. Link the primary research or keep the point qualitative.
That trade-off matters at the C level. A better network does not just lower shipping cost. It gives you more control over growth. You can support retail and DTC at the same time, reduce peak concentration risk, and route orders based on service economics instead of warehouse habit.
I would not expand from one node until three things are true. Customer demand is concentrated in at least one additional region. The SKU mix is stable enough to forecast regional placement with some confidence. The systems can keep inventory truth clean across locations.
Start with the economics:
That last question gets missed. Some brands open a second node and spread inventory too thin. They gain a little speed and lose control of availability. Others keep every SKU centralized and miss the chance to lower shipping cost on the products that drive volume. The smarter approach is mixed placement. Put proven fast movers into regional nodes. Keep tail SKUs, complex kits, and unpredictable items in a primary hub until the routing data supports a wider rollout.
A distributed network increases execution complexity upstream. More receiving points mean more chances for PO errors, ASN misses, prep failures, and late inbound handoffs. If suppliers are inconsistent, adding nodes can multiply friction instead of reducing it.
That is why supplier governance has to tighten before network expansion.
A working supplier scorecard should grade performance on the factors that create downstream cost:
| Supplier dimension | What to look for |
|---|---|
| Reliability | On-time shipment performance, lead-time consistency, issue communication |
| Quality discipline | Defect rates, packaging accuracy, prep compliance |
| Flexibility | Ability to support staggered deliveries and forecast changes |
| Risk profile | Geographic concentration, freight lane exposure, compliance risk |
| Documentation quality | PO accuracy, carton labels, ASN readiness, packing list consistency |
Documentation sounds minor until you run multiple nodes. Then it becomes operating discipline. If purchase orders are inconsistent, receiving teams spend time resolving preventable errors, inventory gets booked late, and order routing starts from bad inputs. Teams tightening this process can use the Monopack ltd PO guide as a practical reference for structuring purchase order numbers and reducing downstream confusion.
The cleanest path is usually one primary node plus one regional node built around a specific objective. Cut parcel cost in the Northeast. Improve two-day coverage on the West Coast. Protect peak capacity with overflow in a region that consistently bottlenecks. Pick one.
Then make the pilot measurable. Do not spread the full catalog across both facilities. Seed a selected group of fast movers with predictable demand and low bundling complexity. Watch the numbers that determine whether the network deserves more capital and management attention:
This is where AI-based orchestration starts to matter. Use it to score node placement risk, recommend replenishment by region, and flag when an inbound delay will create a service failure in one node before it shows up in CX tickets. Operators still make the trade-off calls. The system should surface the highest-cost exceptions first.
A scalable network is not the one with the most buildings. It is the one that places the right inventory in the right node, keeps inbound disciplined, and gives leadership options when demand shifts or disruption hits.
At a certain scale, the problem stops looking like fulfillment and starts looking like delayed judgment. Orders are in. Inventory exists somewhere. A supplier slips a date, parcel costs drift, promise dates get missed, and the team still spends half the day stitching together exports to decide what matters first. That is the point where technology becomes an operating system for decisions, not a collection of apps.

For a 7 to 9 figure brand, the goal is not more dashboards. The goal is one decision layer that connects diagnostics, execution, and risk signals tightly enough that operators can act before margin leaks out. That usually means getting clear on the role of each system. OMS controls order routing logic. WMS controls inventory truth and warehouse execution. TMS controls carrier selection, movement, and freight visibility. AI should sit across that stack to prioritize exceptions, estimate downstream impact, and help the team work the highest-cost problem first.
Priority should follow pain, not software category trends.
If inventory accuracy is weak, fix warehouse truth first. If warehouse execution is stable but routing logic creates split shipments and parcel waste, focus on order orchestration and transportation logic. If the tools are already in place and every team still argues over whose numbers are right, pause the buying cycle and clean up integrations, master data, and ownership.
The operating question has to be specific. “We need more visibility” is not specific. “We need to know which inbound delays will create stockouts for our top 20 SKUs in the next 14 days, by channel and node” is specific enough to build workflows around. Good systems answer narrow, expensive questions quickly.
A useful control tower is not a glossy screen in a boardroom. It is a working environment where ops, planning, and finance can see the same exception set and make the same trade-offs with the same facts.
It should answer a short list of questions without forcing the team into spreadsheet reconciliation:
That last point matters. Mature operators do not need more alerts. They need ranked alerts with business context.
For leaders expanding cross-border complexity, I like practical resources on mastering global supply chain strategies because international operations expose weak data models, poor landed-cost visibility, and bad exception routing fast.
I have seen expensive platforms fail for a simple reason. The demo looked better than the deployment plan.
Tool selection should start with ugly operational details. Can it handle kits, bundles, replacement orders, channel-specific routing rules, lot tracking, and multiple fulfillment partners without custom workarounds everywhere? Does it sync cleanly with Shopify, Amazon, ERP data, and 3PL systems at the speed your team needs? Who owns field mapping, workflow design, testing, and cutover when something breaks on day three?
Use this lens during evaluation:
A simpler platform with clean process design usually beats a feature-heavy platform that lands on top of broken workflows.
Here’s a useful walkthrough to ground that thinking in practical terms.
Too many software evaluations stop at license cost versus labor savings. That is a narrow lens for a supply chain that is already large enough to create seven-figure mistakes through late decisions.
The better question is whether the stack improves the decisions that control cash, service, and margin:
Ask one more question before signing anything. Which recurring decision will this system help the team make faster and with better inputs?
If that answer is vague, the platform will become another reporting surface. If the answer is concrete, you are building an efficiency engine that compounds.
Efficiency without resilience is fragile. You can run a very lean operation right up until one supplier misses a production window, one lane backs up, or one warehouse gets overloaded. Then the whole system reveals whether it was efficient or under-protected.
The pattern is familiar. A supplier pushes a production date. Inbound bookings slip. Inventory arrives late into the main warehouse. Marketplace stock depletes first, because that channel turns fastest. The team starts reallocating inventory manually, customer support gets flooded, and finance sees margin compress because everyone approved expedites to buy time.
That scenario usually isn’t caused by one bad event. It’s caused by the absence of a contingency design.
You don’t need backup for everything. You need backup for the points of failure that create outsized damage.
For most growth-stage e-commerce brands, those points are usually:
That’s where supplier diversification matters. Not fake diversification where you onboard extra vendors no one develops. Real diversification means at least one credible alternative source, documented qualification standards, and a practical plan for shifting volume if needed.
Founders often say they want more resilience. That isn’t actionable. Specific scenarios are.
Run tabletop drills around real disruption cases:
For each scenario, your team should know:
AI-driven risk monitoring offers practical utility. It’s not just about visibility. It’s about combining internal signals with external signals so operators can act before service levels collapse. The strongest teams don’t wait for a supplier to say there’s a problem. They watch for patterns that suggest one is forming.
One of the most common mistakes in risk management is assuming a better platform solves response quality. It doesn’t. Systems can flag issues. People still decide what to do.
That means resilience needs operating rules:
The best disruption playbooks remove debate in the first hour. If your team is still arguing about priorities when the issue hits, the system isn’t prepared.
There’s also a leadership discipline here. Don’t optimize so tightly that every buffer looks like waste. Strategic slack is often what keeps a manageable delay from becoming a company-wide fire drill.
A $20 million brand rarely breaks because one metric slips. It breaks when inventory policy, routing logic, supplier decisions, and exception handling drift out of sync. Revenue can still look healthy while margin, cash, and service get worse.
That is why the payoff from this playbook shows up across the system, not in one dashboard tile. Once diagnostics, fulfillment design, and AI-supported risk controls start working together, operators stop solving the same preventable problem three different ways. Inventory gets positioned with more intent. Freight stops absorbing every planning mistake. Finance gets a cleaner read on what growth is costing.
The before-and-after view below is directional. It shows the operating shape of a stronger business after the pieces are aligned.
| Metric | Before Playbook | After Playbook | Impact |
|---|---|---|---|
| Logistics cost profile | Freight decisions driven by reactive routing and single-node constraints | Better routing discipline and a fulfillment network designed around order density, service targets, and exception patterns | Lower parcel and expedite spend. Fewer margin leaks from bad routing decisions. |
| Inventory position | Capital tied up in excess stock and uneven allocation | Stock levels matched more closely to demand patterns, lead times, and channel priority | Less cash trapped in the wrong SKUs. Better in-stock performance on products that actually drive revenue. |
| Service efficiency | Teams manually chase exceptions and respond after delays happen | Faster intervention through automation, clearer ownership, and earlier risk signals | Less manual firefighting. Faster resolution when issues hit. |
| Cash-to-cash cycle | Cash remains tied up too long due to inventory drag and slow operating feedback | Faster turns through tighter replenishment control and cleaner decision loops | Better cash mobility. More room to fund growth without forcing every problem through working capital. |
| Overall supply chain cost structure | Cost savings depend on ad hoc vendor pressure and firefighting | Lower total cost through coordinated planning, sourcing, fulfillment, and risk management | Cost improvement that holds up under scale, instead of disappearing during peak or disruption. |
| Inventory holding burden | Broad assortment held too heavily across slow-moving stock | Tighter SKU discipline and healthier deployment across nodes and channels | Lower holding burden, fewer aged units, and less discounting to clean up planning mistakes. |
The primary benefit is operating range. Brands that build this way can push into new channels, add volume, and handle volatility without turning the supply chain into a tax on growth.
If you’re running an Amazon, DTC, or omnichannel brand at scale and want sharper operator-to-operator insight on challenges like this, Million Dollar Sellers is where serious founders compare playbooks, pressure-test decisions, and learn what’s working behind the scenes in 7-, 8-, and 9-figure businesses.
Join the Ecom Entrepreneur Community for Vetted 7-9 Figure Ecommerce Founders
Learn MoreYou may also like:
Learn more about our special events!
Check Events

